
感谢 GitHub 的alsotang 提供的开源学习项目 node-lessons ,昨天看了一天收获还是不少,不过有些点还不是很理解。今天总结了一下,基本吸收的知识点。
知识点
- 使用 Express 实现简单的node服务
- 使用 superagent 抓取网页
- 使用 cheerio 分析网页
1. 使用 Express 实现简单的node服务
1.1 Express 框架介绍
Express 基于 Node.js 平台,快速、开放、极简的 Web 开发框架
1.2 项目初始化
前提是要安装 Node.js
接下来新建一个目录
mkdir myapp
并切换到新建好的目录下:
cd myapp
通过 npm init -y 命令初始化项目,这时候会生成一个 package.json的文件,这个文件是个好东西,想了解更多请前往 Specifics of npm’s package.json handling.
接下来在 myapp 目录下安装 Express 并将其保存到依赖列表中。如下:
npm install express --save
新建一个app.js 文件,输入一下代码:
// 加载 express 模块
const express = require('express')
// 实例化 express
const app = express()
//
app.get('/', (req, res) => {
res.send('Hello Express')
})
// 端口监听
app.listen(3000, () => {
console.log('server is running at http://localhost:3000')
})
执行一下命令:
node app.js
这时候终端会输出相关的打印信息,
通过谷歌访问localhost:3000就可以看到Hello Express
小结
到这里一个简单的 express 应用已经完成了,接下来就是通过 superagent 和 cheerio 实现一个简单网页爬虫
2. 简单的网页爬虫
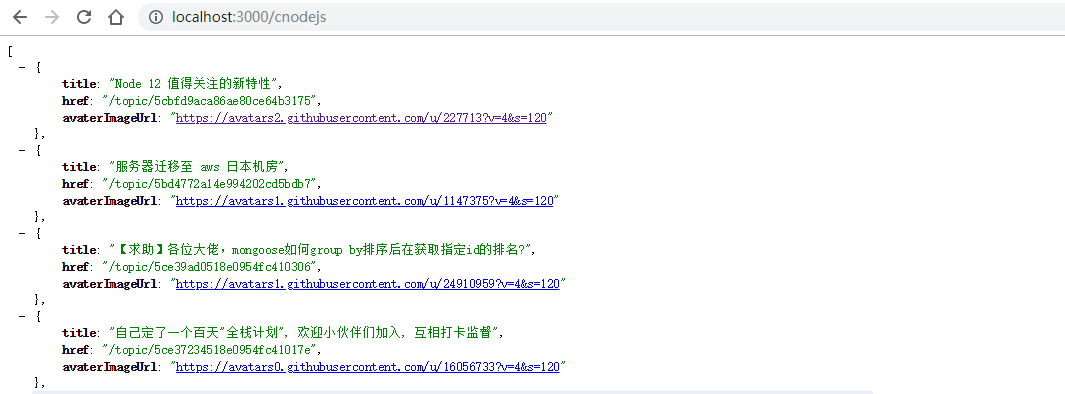
这里是在上面的基础上继续完成来实现这个简单的网页爬虫,通过访问localhost:3000时,以 json 的形式在页面显示输出 CNode(https://cnodejs.org/ ) 社区首页的所有帖子标题和链接。
依赖介绍:
- superagent 一个用来发 http 请求的库
- cheerio,Node.js 版的 jQuery ,主要是用来读取网页的节点属性和相应的值
插件安装:
npm install superagent cheerio --save
在app.js引入相关的依赖:
const superagent = require('superagent')
const cheerio = require('cheerio')
核心代码:
app.get('/', (req, res, next) => {
// 1. 用 superagent 去发起请求抓取 https://cnodejs.org/ 的 html 内容
superagent.get('https://cnodejs.org/')
.end((err, res) => {
// 2. 错误判断处理
if (err) {
return next(err)
}
/**
* 3. res.text 是存网页 html 内容
* 4. 将爬取到的内容传到 cheerio.load(res.text) 方法进行节点的读取
* 5. 接下来就是 jQuery的操作获取节点的值了
*/
var $ = cheerio.load(res.text)
var items = []
$('#topic_list .topic_title').each((idx, element) => {
var $element = $(element)
items.push({
title: $element.attr('title'),
href: $element.attr('href')
})
})
// 6. 发送到页面显示
res.send(items)
})
})
最终代码:
const express = require('express')
const superagent = require('superagent')
const cheerio = require('cheerio')
const app = express()
app.get('/', (req, res, next) => {
superagent.get('https://cnodejs.org/')
.end((err, res) => {
if (err) {
return next(err)
}
var $ = cheerio.load(res.text)
var items = []
$('#topic_list .topic_title').each((idx, element) => {
var $element = $(element)
items.push({
title: $element.attr('title'),
href: $element.attr('href')
})
})
res.send(items)
})
])
app.listen(3000, () => {
console.log('server is running at http://localhost:3000')
})
启动:
node app.js
总结
一个简单的网页爬虫到这里就完成啦!! 不过并发过高会被ip可能会被封。建议多看官方文档。